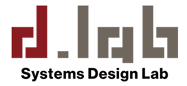
スケーリングシナリオ
指数関数の驚異
2020.04.18
理想的なスケーリングシナリオ
集積回路の発展のための基本原理は、デバイスを微細化してスケーリングすることです。集積度を高めてチップの製造コストを安くし性能を高めます。
DRAMは3年で4倍ずつ、プロセッサは2年で2倍ずつ、集積度が高くなってきました。こうした経験則は、「ムーアの法則」として広く知られています。
チップの製造コストは、ウェハー1枚あたりの製造コストを1枚のウェハーから取れる良品チップの数で割った値です。
リソグラフィとプロセスの技術を進化させて、デバイスをスケーリングします。同時に、ウェハー口径を大きくしたり、製造技術を改善することで歩留まりを高めて、良品チップの数を増やします。
過去50年間を振り返ると、2年ごとに、デバイスは20%微細化されチップサイズは14%大きくなっています。その結果、集積できるデバイスの数は2年ごとに倍増(=1.142/0.82)してきました。
DRAMでは、さらにデバイスを3次元構造にしたり回路を工夫するなどして、3年で4倍の高集積化を果たしてきました。もっとも、こうした工夫はそろそろ限界に近づき、DRAMのスケーリングは間もなく止まるとも言われています。
次に、性能がどうなるかを議論しましょう。デバイスの寸法x [m]に加え電圧V [V]も1/αに低くすると(20%縮小の場合はα=1.25)、トランジスタ内部の電界[V/m]を一定に保てます。この「電界一定のスケーリング」によって、電界効果トランジスタはスケーリングの前後で等しい動作が保証されます。
このとき、トランジスタを流れる電流I [A]と容量C [F]も1/αに小さくなります。その理由は概ね次のとおりです。
電流Iは、電荷が流れる速度なので[C/s]、ゲートの電界効果によって誘起したチャネル方向の電荷密度[C/m]と、ドレイン・ソース間の電界によってチャネルを移動する電荷の速度 [m/s]の掛け算で決まります。電荷密度は、チャネル方向あたりの容量とゲート・チャネル間の電圧 [V]の掛け算で決まり、チャネル方向あたりの容量はチャネル幅[m]÷ゲート絶縁膜の厚さ[m]で決まります。一方、電荷速度はドレイン・ソース間の電界つまりドレイン・ソース間電圧[V]÷チャネル長[m]で決まります。
整理すると、IはV2/xに比例するので、スケーリングで1/αに小さくなります。また、容量Cは面積÷距離で求まるのでxに比例して、1/αに小さくなります。
電圧V [V]、I [A]、容量C [F]がそれぞれ1/αに比例縮小されると、回路の遅延時間は1/α倍に小さくなります。容量Cと抵抗R(=V/I)の積で決まるRC時定数が1/αに小さくなるからです。RCが時間の次元を持つことは、Q = CVとQ = It (tは時間)をtで解いて、t = CV/I = RCとなることからも理解できます。
ここで、電力密度[W/mm2]を計算すると、電圧×電流÷面積で計算できますから、スケーリングしても一定で変化しません。集積度が上がると放熱が難しくなるように感じますが、電力密度は一定なので、放熱の問題は起きません。まことに理想的なシナリオです。
実際のスケーリングとその副作用
しかし、実際には理想通りに事が運びませんでした。
マイクロプロセッサの動作周波数は、10年間でおよそ50倍に高速になりました。そのうち13倍がスケーリングによる効果で、残りの4倍がアーキテクチャによる改善です。
換算すると、動作速度は2年で1.6倍ずつ高速化されたことになります。電界一定のスケーリング則では1.2倍のはずですから、随分高速にしたことが分かります。
実は、1995年まで電源電圧を低くせずにデバイスをスケーリングしました。つまり「電界一定」ではなく「電圧一定」でスケーリングしたのです。
その場合、電流Iはα倍に増え、容量Cは1/αに小さくなるので、回路の遅延時間は1/α2に小さくなり、回路はさらに高速で動作します。しかし、電力密度はα3で急増してしまいます。
こうした理由は、処理性能が高いほどチップがよく売れたからでした。一方でチップの電力は当初十分に小さかったので、電力の増大はさほど大きな問題ではなかったのです。
1980年から1995年の15年間にチップの電力は1,000倍に増えました。その結果、単位面積あたりの発熱量は調理用ホットプレートの30倍にも達してしまいました。
放熱ができないと、デバイス内部の温度が高くなり、信頼性が損なわれます。電力の壁にぶつかると、回路をそれ以上集積できなくなります。
このように、電力の壁の原因は、アグレッシブなスケーリングの副作用だったのです。
1995年以降は、電源電圧を徐々に下げました。
当然のことですが、回路を使わないときは電源をこまめに切ったり、高い性能が要らないときには電源電圧を下げるなど、電力を節約する細かな努力も積み重ねてきました。
これらのことは日常生活でも行われている当たり前の節約に聞こえますが、1億個以上のトランジスタを集積した大規模集積回路になると、無駄に気づくことからして容易ではありません。
電源電圧の理論的下限値は、室温の場合0.036Vです。これ以下にすると、CMOS回路の利得が1を切り、デジタル回路を多段に接続できなくなります。
しかし実際には、オフしているトランジスタのリーク電流やデバイスのばらつき、ノイズなどがあり、0.45V以下に下げるのはとても困難です。
28nm世代以降は、集積はできても同時には使えないトランジスタ、つまり「ダークシリコン」(電源投入できずに暗いままのトランジスタ)が急増しています。機能は集積できても性能を引き出すことが困難になっています。
したがって、電力効率を改善できた人だけが、性能を改善できます。まさに「電力効率の改善なくして性能改善なし」です。
電源電圧を下げる以外に電力効率を改善する手段は、容量Cの削減です。そのために、チップを積層して3次元に集積する技術が、今後の集積回路の命運を握ります。つまり集積のレベルを2Dから3Dに拡張することです。なぜなら、チップの厚さはチップの幅に比べると3桁も小さいので、チップを3次元に積層すればチップ間の接続距離を桁違いに短くできるからです。
指数関数の驚異を私たちは直観できない
池の鯉を世話する老人がいました。十分な酸素が水中に届くように、時折蓮の葉を摘み取って池を守っていました。蓮の葉はそれほど急に増えるものではないので、まあ大丈夫だろうと1週間ほど留守にすると、池はすっかり蓮の葉に覆いつくされていました。
この話は、指数関数の特徴をよく表しています。(そしてコロナ感染数の増大もこれと同じです。)
私たちの直観は、変化する事象を直線近似に捉えます。太古の昔、ジャングルの中で猛獣(等速運動)から身を守るために獲得し、DNAに刻まれた感覚です。現代社会になっても、これまでの変化を直線で外挿して未来を予測することは多いです。
しかし、チップが創る世界は指数関数で成長します。AIもその一つです。AIが突然この世に現れ、直後には空高く舞い上がるように急成長する理由は、ここにあります。
チップが生み出すデータも指数関数的に急増しています。インターネットの通信量は、年率4倍で急増しています(Gilder's Law)。
21世紀後半には、全人類の脳のニューロンの総数に匹敵するトランジスタが一つのチップに集積できるかもしれません。さらに世界中のチップが無線接続されて巨大な頭脳が地上に出現することも、夢物語ではありません。
集積回路の発明からわずか100年の間に、世界は劇的に変化しています。