2Dから3Dへ
集積回路の次の半世紀
2020.04.26
大規模システムの接続問題
集積回路(チップ)の発明の背景には、大規模システムの接続問題がありました。
1946年に開発された電子計算機ENIACには、手作業による接続が500万箇所もありました。システムが大規模になると、接続数が幾何級数的に増加します。
この問題は、Tyranny of Numbers(数の暴威)と呼ばれ、さまざまな角度から対応策が検討されましたが、その中から生まれた決定的な解が集積回路でした。
それ以来、チップが「ムーアの法則」で指数関数的な成長を遂げ、それと歩調を合わせてコンピュータの性能も飛躍的に向上しました。
しかし、メモリとプロセッサの間を大量のデータが移動するために、チップ間の通信がエネルギー効率を低下させる要因となりました。いわゆるフォン・ノイマン・ボトルネックです。
さらにデータの急増も相まって、「エネルギー効率の改善なくしてコンピュータの性能改善なし」という状況になり、それは現在も続いています。
CMOS回路の消費エネルギーは、負荷容量に比例します。演算回路の負荷容量は、デバイスの微細化で小さくできます。
しかし、データの移動では通信路に沿った全容量を充放電しなければなりませんから、デバイスを微細化しても通信距離が変わらなければ消費エネルギーを低減できません。
演算よりもデータの移動がはるかに大きなエネルギーを消費します。
たとえば64ビットのデータを演算するのに比べて、そのデータをチップの端まで移動するのに50倍のエネルギーが必要になり、さらにチップの外にあるDRAMに移動するのに200倍のエネルギーが必要になります。
チップ間の通信が大きなエネルギーを消費するようになったもう一つ理由は、転送速度を強引に高速化したからです。その背景には、通信チャネルをチップの周辺にしか配置できないので、その数を増やせないことがあります。
まず、チップの演算性能は年率70%ずつ向上します。トランジスタが15%高速になり機能の集積度が49%増加した結果です。
チップの性能が高くなった分チップに出入りする信号の速度も高速にしなければ、高くなった性能を生かすことができません。
論理規模の拡大に応じて入出力の端子数をどれだけ増加させる必要があるかについての経験則である「レンツの法則」から類推すると、チップ間の信号転送を年率44%で高速化することが求められます。
しかし、デバイスのスケーリングでは、チップ間の通信速度を年率28%しか高速化できません。トランジスタは15%高速になるのですが、信号はチップの周辺からしか出入りできないので機能の集積度を11%しか増大できないからです。
仮にチップの全面に信号チャネルを配置しても、回路基板が十分な多層構造でなければチップの周辺で配線が込み合うので、チップの全面を利用するのは困難です。
このギャップを埋めるために、通信チャネルを高速化する回路技術を駆使してきました。しかし、一般にも言えることですが、トランジスタの性能限界まで強引に性能を引き出そうとすると大きなエネルギーが必要になります。
チップ間通信に必要なエネルギーは、130nm世代(2000年)頃から増加に転じています。そしてこれ以上の高速化はそろそろ限界に近づいています。
以上の議論からお分かりのとおり、コンピュータのエネルギー効率を高める方策は、メモリとプロセッサの接続距離を短くして、かつ、接続数を増やし無理のない速度で信号転送することです。
つまり、チップを積み重ねて短距離に接続し、面全体を使って程よい速度で通信すべきです。チップが2D(平面)から3D(立体)に進化する理由がここにあります。
チップ内での集積のみに頼ることができなくなり、2Dから3Dへとチップが進化する現在において、一段と画期的な「接続問題の解」が求められています。
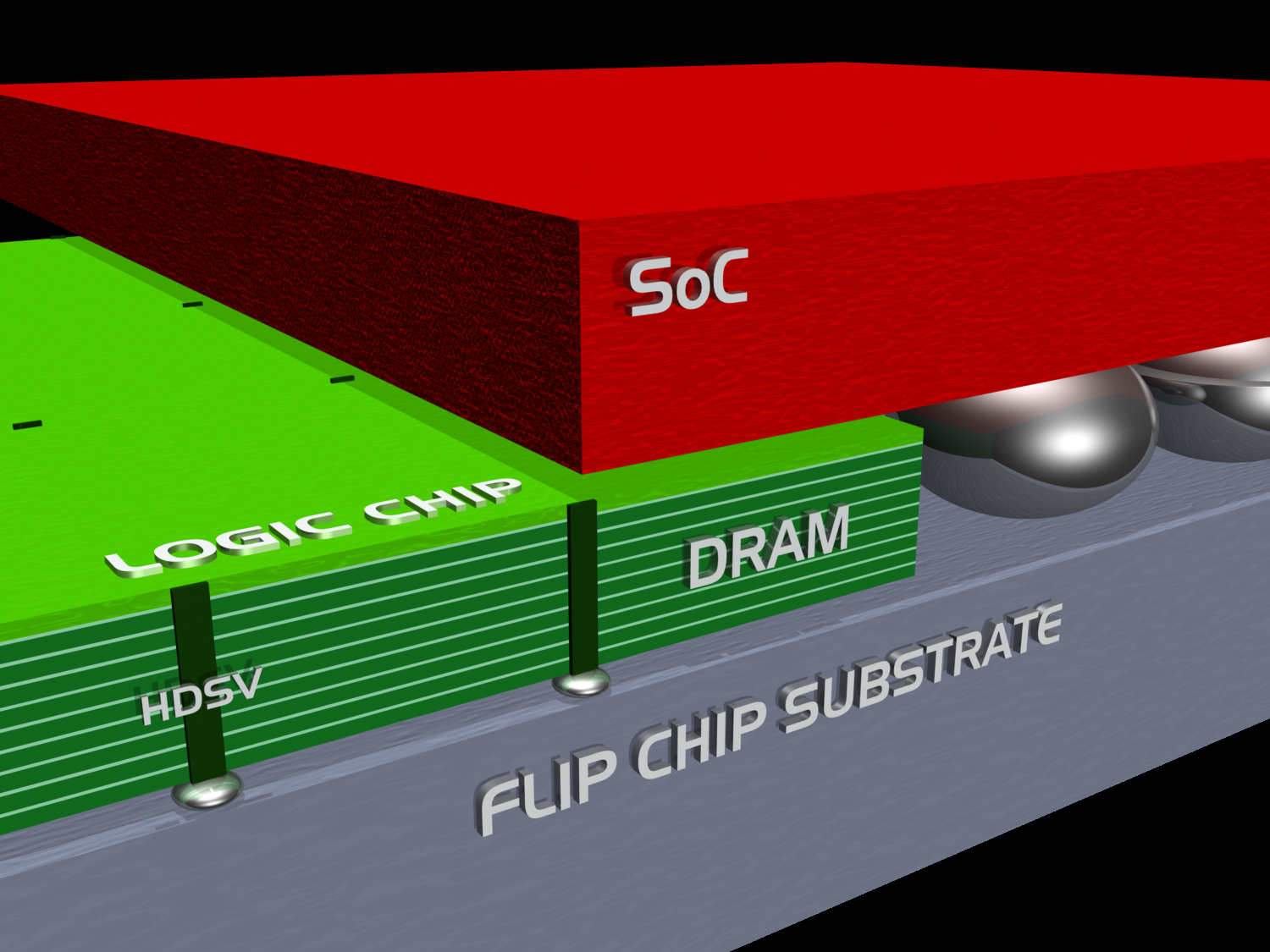
シリコン貫通電極と磁界結合通信
そこで、チップを積層して垂直方向に配線接続するシリコン貫通電極 (TSV; Through Silicon Via)の研究開発が1990年代に始まりました。以前はチップの表面から数ミクロン以内を加工していたのに対して、今回は数10ミクロンを加工するのですから、容易ではありません。
加えて、半田接続の微細化がとても困難でした。また、材料の熱膨張係数の違いから生じる応力も信頼性の問題も生じました。
TSVは、いまだにコストが高く信頼性が低いです。既に四半世紀が経った今でも、解決の道が見えていません。
この問題を解決したのが、磁界結合通信(TCI; ThruChip Interface)でした。これはチップの配線でコイルを巻き、デジタル信号に応じてコイルを流れる電流の向きを変えて磁界の向きを変化させ、他のチップでコイルに生じる信号の極性を検知してデジタル信号に戻す方式です。つまり、コイル間の磁界結合でチップ間通信を行うものです。
半導体チップに用いられる材料はいずれも透磁率が1なので、磁界はチップをきれいに貫通できます。また、電界効果を利用するCMOS回路と干渉する心配がありません。
そして、TSVがパッケージ組立工程で機械式に接続するのに対して、TCIはウェハー工程で標準CMOS回路で電子式に接続する点が最大の特長です。
TCIは、チップの製造プロセスを変えずにデジタル回路技術で実現できるので、誰でも安く実現できます。TSVだとDRAMの値段が1.5倍以上高くなりますが、TCIなら値段を1.1倍以下に抑えることができます。
さらに、チップを薄くするほどTCIの性能コスト比を指数関数的に改善できます。
たとえば、チップを1/2に微細化し、加えてチップの厚さを1/2に薄化すれば、TCIのデータ転送速度を8倍に高め、エネルギー消費を1/8に低減できます。
ただし、TCIは電源を接続できません。電源接続はTSVで行い、信号接続はTCIで行うのが現実的です。それならば信号接続もTSVでいいではないかと疑問に思われるでしょうが、実はTSVの不良はオープン不良です。したがって、冗長にし難い信号線には使いにくいですが、もともと超並列に接続されている電源線には問題なく使えます。
TSVに代えて、高濃度の不純物領域で電源接続を行う新技術(HDSV; Highly Doped Silicon Via)の研究開発も始まっています。
このようにチップが2Dから3Dに進化することで、チップのエネルギー効率は高くなります。しかし、複数のチップを積層すると電力密度は高くなるので、電力効率をさらに改善しなければ放熱できなくなります。
不連続な技術を生かせる時代
研究と実用の間に横たる死の谷。不連続な技術(disruptive technology)はこの死の谷を越えることがなかなかできません。
接続技術は、接続される両者の了解が必要になります。
プロセッサの会社に行ってTCIを紹介すると、身を乗り出して話を聞いてもらった後に、メモリにはいつTCIが搭載されるのかを尋ねられます。
そこでメモリ会社に行き、プロセッサの会社がTCIに強い興味を示していることを伝えると、席に深く腰掛けたまま、大口の客がみんな使うと言わなければ大幅な変更を伴う新技術の導入は難しいと渋い顔をされます。メモリビジネスは汎用品ビジネスなので、このようにいつも保守的です。
これでチキン・アンド・エッグ・プロブレムの迷宮から抜け出せなくなります。
しかし、エネルギー効率の改善なくしてコンピュータの性能改善なしという状況に追い込まれ、そこから脱するためには2Dから3Dへと集積回路の新たな時代の扉を開かざるを得なくなりました。不連続な技術(革新的技術と呼びたい)にとっては、チャンス到来です。
それでもメモリ会社を動かすのは容易でなないので、まずはSRAMを積層してDRAMに匹敵する大容量を実現し、プロセッサと接続することから始めるのが良いと考えています。SRAMはプロセッサの会社が開発できるので、単独で決断できるからです。そしてDRAMのスケーリングがそろそろ止まりそうだからです。